



Feature encoding is the process of transforming data into a format that can be used by Machine Learning algorithms. This is often necessary when working with real-world data, which can be messy and unstructured. There are many different ways to encode data, and the choice of technique will depend on the type of data and the machine learning algorithm being used.
What is encoding?
As we all know, Machine Learning only deals with numerical data and converting categorical data into numerical data is referred to as encoding .
Basics of encoding
Here are some of the more well-known and widely used encoding techniques:
Label encoding: Label encoding is a method of encoding variables or features in a dataset. It involves converting categorical variables into numerical variables.
One-hot encoding: One-hot encoding is the process by which categorical variables are converted into a form that can be used by ML algorithms.
Binary encoding: Binary encoding is the process of encoding data using the binary code. In binary encoding, each character is represented by a combination of 0s and 1s.
For Example:
- 0000 - 0
- 0001 - 1
- 0010 - 2
- 0011 - 3
- 0100 - 4
- 0101 - 5
- 0110 - 6
- 0111 - 7
- 1000 - 8
- 1001 - 9
- 1010 - 10
Detailed explanation of feature encoding
Datasets generally consist of 2 types of features:
- Numerical (Integer,floats)
- Categorical (Nominal, ordinal)
Most of the Machine learning algorithms cannot handle categorical variables unless we convert them to numerical values. Many algorithm’s performances vary based on how categorical variables are encoded.
Categorical variables are of 2 types - Ordinal and Nominal.

- Ordinal variables have some kind of order. (Good, Better, Best), (First, Second, Third)
- Nominal variables have no particular order between them. (Cat, Dog, Monkey), (Apple, Banana, Mango)
Based on whether the categorical variables are ordinal or nominal, we apply different techniques on them.

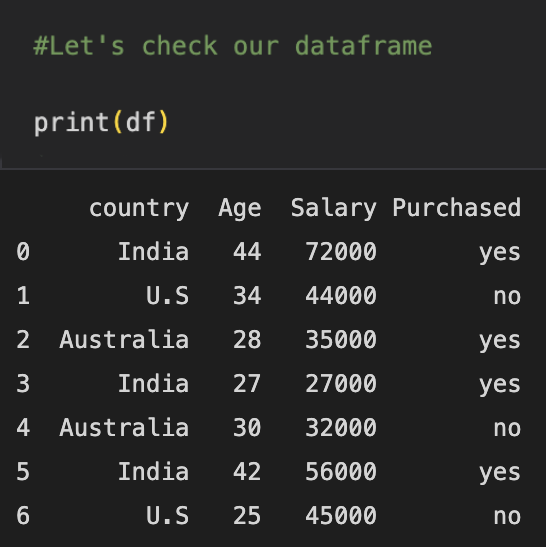

Here we have two categorical features:
- Country
- Purchased
Age and Salary have numeric values.
We know it well that we cannot pass categorical values through our models.
- Label Encoding

So, here we have 3 categories in the country column.
India, U.S, and Australia
In label encoding, different categories are given different unique values starting from 0 to (n-1). n is the number of categories.

Here, we can see that the country features have been transformed into numeric values. Label encoding is done in alphabetical order as we can see in the picture above. Australia -----> 0 India --------> 1 U.S ---------> 2
Problem with label encoding
We have assigned numeric values i.e (0-Australia), (1-India), (2-U.S) in the same column. The problem here is that Machine Learning models won’t interpret these values as different labels because 0 < 1 < 2. Our model might interpret them in some order. However, we don’t have any ordering in terms of countries. We cannot say Australia < India < U.S.
We use one-hot encoding to overcome this problem.
- One-hot encoding
One-hot encoding is also known as nominal encoding. Here, we create 3 different columns [India, Australia, U.S]. We assign 1 if that label is present in a particular row otherwise we mark it as 0.

In the first row [‘India’] is assigned 1 and Australia and U.S are assigned 0. Similarly in the 2nd row [‘U.S’] is assigned 1 and other columns are assigned 0.
We can drop the first column here, since it is just increasing the features. Reason ---- even if we just have two columns (suppose India and U.S), it is understood that when both of these labels are zero, the 3rd label is automatically going to be 1.

In the above example, we have done one-hot encoding only on a single feature but in real world datasets, there will be many categorical features. Suppose our dataset has 50 categorical features with 3 different labels in each feature. In that case, if we apply one-hot encoding, our features will also increase. We will have 100 features and it will make our model more complex.
Based on the dataset, there are different techniques that we can apply to overcome this problem of dimensionality.
- Binary encoding This encoding feature is not intuitive like the previous ones. Here, the labels are firstly encoded ordinally and then they are converted into binary codes. The digits from that binary string are then converted into different features.

We have seven different categories here and we don’t have any ordering in them either.


We had 7 different categories in occupation. If we had used one-hot encoding, it would have given us 7 features. However, by using binary encoding, we have limited it to 3. Binary encoding is very useful when we have many categories within a single feature. It helps us reduce the dimensionality.
Overall, feature encoding is a powerful tool that can be used to improve the performance of Machine Learning models. However, it is important to remember that there is no single best way to encode features and that the best approach may vary depending on the data and the task at hand.
In addition, it is important to keep in mind that not all Machine Learning algorithms are able to handle categorical features and that some may require the features to be encoded in a specific way. Finally, it is always worth experimenting with different encoding schemes to see what works best for your data and your task.
If you are intrigued by the Data Science and Analytics field and want to become a part of it, enrol for our flagship Full Stack Data Science program. Apart from a dynamic tech community, the program offers 100% placement guarantee and top-notch training as per industry standards.
Read our latest blog on “Types of Recommendation Systems: How they work and their use cases”.





