

Data Science
Customer Churn Prediction Using Machine Learning (with code)
Last Updated: 1st February, 2024

Narender Ravulakollu
Technical Content Writer at almaBetter
Discover customer churn prediction with machine learning in Python using Telco dataset and learn about building a model to retain customers and reduce churn.

Customer churn is a critical problem for any business as it can significantly impact revenue and growth. To overcome this challenge, companies need to identify the customers who are more likely to churn and take proactive measures to retain them. One effective way to achieve this is through customer churn prediction using machine learning.
In this article, we will explore the process of customer churn analysis and demonstrate how to predict customer churn with machine learning in Python. We will cover data preparation, feature engineering, model training, and evaluation to help you develop an accurate churn prediction model.
Requirements:
To perform customer churn prediction using machine learning in Python, there are a few requirements that need to be fulfilled.
Dataset: A dataset containing customer data is required to perform customer churn analysis and prediction. The dataset should include features such as customer demographics, transaction history, and interactions with the company.
Python: Python is the programming language used for this task. Therefore, you need to have Python installed on your system. Python can be downloaded from the official Python website and installed on your computer.
Machine learning libraries: Python has several machine learning libraries, such as scikit-learn, TensorFlow, and Keras, that can be used to build machine learning models.
Data preprocessing libraries: Before training the machine learning model, the data needs to be preprocessed to clean and transform it into a format suitable for the model.
Integrated Development Environment (IDE): To write and execute Python code, you need an Integrated Development Environment (IDE). There are several IDEs available for Python, such as PyCharm, Spyder, and Jupyter Notebook.
By fulfilling these requirements, we can perform customer churn prediction using machine learning in Python.
Required Modules:
To perform customer churn prediction using machine learning in Python, we need to import several modules that provide various tools and algorithms for data preprocessing, model training, and evaluation. Here are the required modules for this task:
Pandas: Pandas is a Python library used for data manipulation and analysis. It provides data structures for efficiently storing and manipulating large datasets.
Numpy: NumPy is a Python library used for numerical operations such as linear algebra, Fourier transform, and random number generation. It provides efficient and optimized routines for numerical computations.
Scikit-learn: Scikit-learn is a Python library used for machine learning tasks such as classification, regression, and clustering. It provides various algorithms and tools for data preprocessing, model training, and evaluation.
Matplotlib: Matplotlib is a Python library used for data visualization. It provides tools for creating various types of plots, such as scatter plots, bar plots, and line plots.
Seaborn: Seaborn is a Python library based on matplotlib used for data visualization. It provides additional tools for creating more complex and informative plots.
Warnings: Warnings module is used to ignore the warning messages that might pop up while running the code.
We can import these modules using the import statement in Python. For example:
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
Code Implementation:
Importing required libraries: We import the required libraries such as pandas, numpy, scikit-learn, matplotlib, seaborn, and warnings. We also filter out any warning messages that might pop up while running the code.
# Importing required libraries
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
Loading the dataset: We load the dataset containing customer data using the Pandas library.
Link to the dataset: https://www.kaggle.com/datasets/blastchar/telco-customer-churn
# Loading the dataset
data = pd.read_csv('customer_churn.csv')
Exploring the dataset: We print the first few rows of the dataset using the head() method to get an idea of what the data looks like.
# Exploring the dataset
print(data.head())
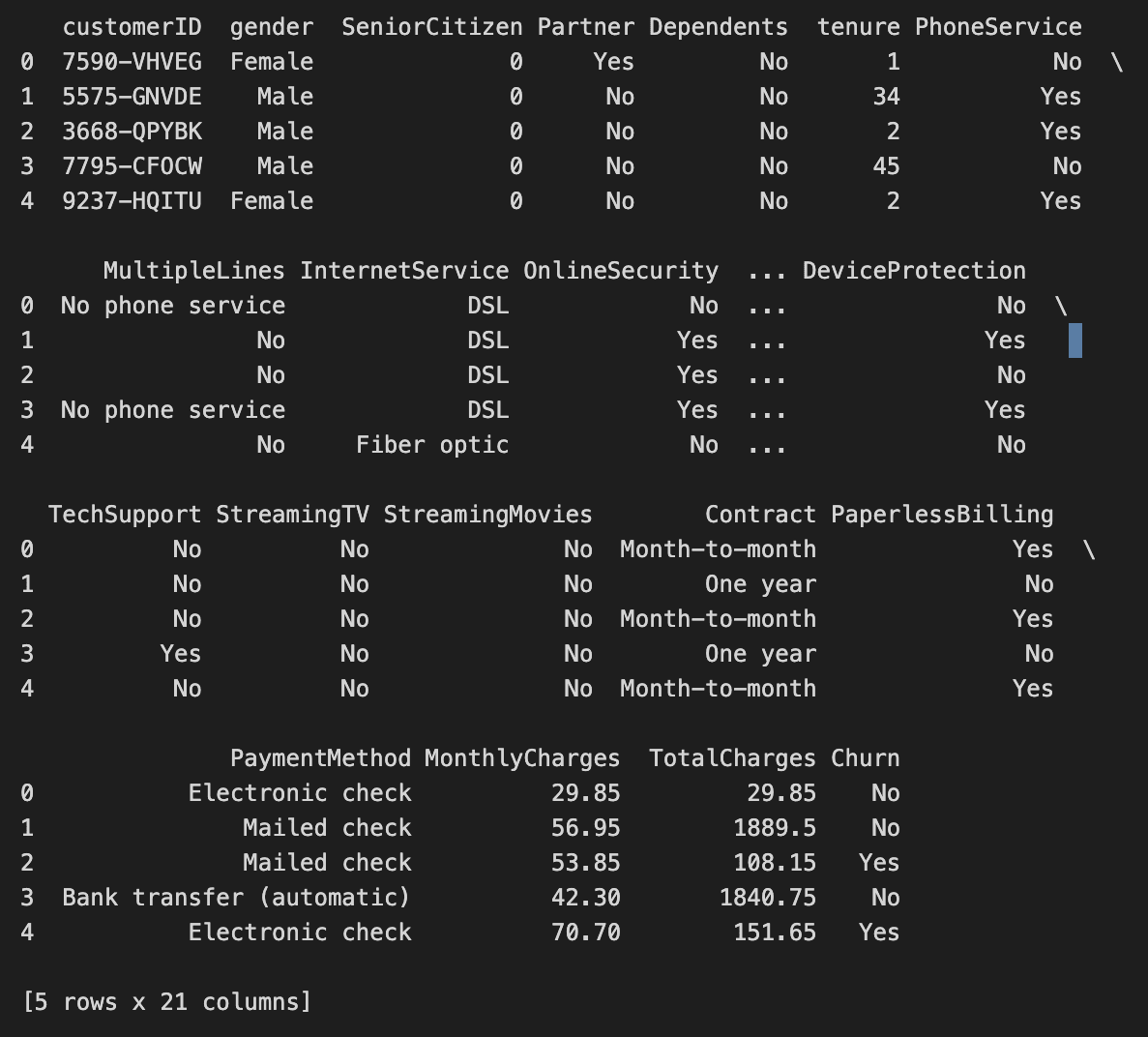
data.head()
Data preprocessing: We preprocess the data by dropping irrelevant columns, converting categorical columns to numerical columns, converting the 'TotalCharges' column to numeric type, and handling missing values.
# Data preprocessing
# Dropping irrelevant columns
data = data.drop(['customerID','MultipleLines','InternetService','OnlineSecurity','OnlineBackup','DeviceProtection','TechSupport','StreamingTV','StreamingMovies','PaymentMethod','Contract'], axis=1)
# Converting categorical columns to numerical columns
data['gender'] = data['gender'].map({'Female': 1, 'Male': 0})
data['Partner'] = data['Partner'].map({'Yes': 1, 'No': 0})
data['Dependents'] = data['Dependents'].map({'Yes': 1, 'No': 0})
data['PhoneService'] = data['PhoneService'].map({'Yes': 1, 'No': 0})
data['PaperlessBilling'] = data['PaperlessBilling'].map({'Yes': 1, 'No': 0})
data['Churn'] = data['Churn'].map({'Yes': 1, 'No': 0})
# Converting 'TotalCharges' column to numeric type
data['TotalCharges'] = pd.to_numeric(data['TotalCharges'], errors='coerce')
# Handling missing values
data = data.dropna()
Splitting the dataset into training and testing sets: We split the dataset into training and testing sets using the train_test_split() method from scikit-learn.
# Splitting the dataset into training and testing sets
X = data.iloc[:, :-1].values
y = data.iloc[:, -1].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
Feature scaling: We perform feature scaling on the training and testing sets using the StandardScaler() method from scikit-learn.
# Feature scaling
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
Training the decision tree model: We train a decision tree classifier on the training set using the DecisionTreeClassifier() method from scikit-learn.
# Training the decision tree model
classifier = DecisionTreeClassifier(criterion='entropy', random_state=0)
classifier.fit(X_train, y_train)
Predicting the test set results: We use the trained model to predict the customer churn for the test set.
# Predicting the test set results
y_pred = classifier.predict(X_test)
Evaluating the model: We evaluate the model's accuracy using the accuracy_score() method and visualize the results using the confusion_matrix() and classification_report() methods from scikit-learn.
# Evaluating the model
print('Accuracy:', accuracy_score(y_test, y_pred))
print('Confusion Matrix:', confusion_matrix(y_test, y_pred))
print('Classification Report:', classification_report(y_test, y_pred))
Visualizing the results: Finally, we use the seaborn library to create a count plot of the churn data to visualize the results.
# Visualizing the results
sns.countplot(x='Churn', data=data)
plt.title('Customer Churn')
plt.show()
Output:
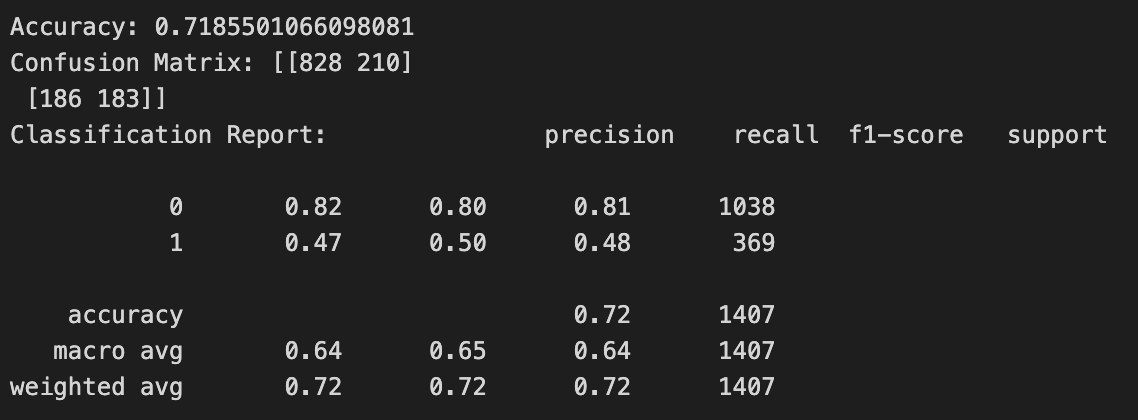
report
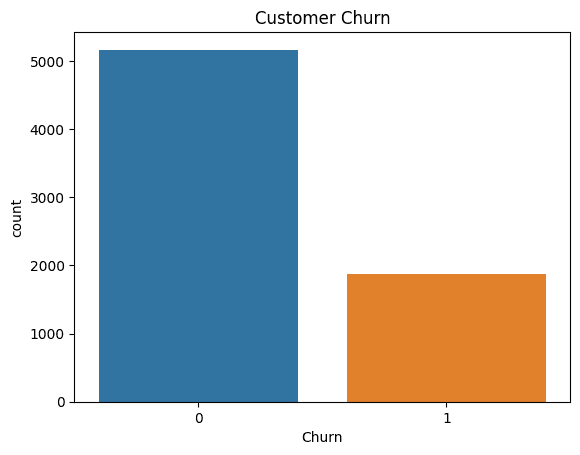
Customer churn chart
Source Code:
# Importing required libraries
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
# Loading the dataset
data = pd.read_csv('customer_churn.csv')
# Exploring the dataset
print(data.head())
# Data preprocessing
# Dropping irrelevant columns
data = data.drop(['customerID'], axis=1)
# Converting categorical columns to numerical columns
data['gender'] = data['gender'].map({'Female': 1, 'Male': 0})
data['Partner'] = data['Partner'].map({'Yes': 1, 'No': 0})
data['Dependents'] = data['Dependents'].map({'Yes': 1, 'No': 0})
data['PhoneService'] = data['PhoneService'].map({'Yes': 1, 'No': 0})
data['PaperlessBilling'] = data['PaperlessBilling'].map({'Yes': 1, 'No': 0})
data['Churn'] = data['Churn'].map({'Yes': 1, 'No': 0})
# Converting 'TotalCharges' column to numeric type
data['TotalCharges'] = pd.to_numeric(data['TotalCharges'], errors='coerce')
# Handling missing values
data = data.dropna()
# Splitting the dataset into training and testing sets
X = data.iloc[:, :-1].values
y = data.iloc[:, -1].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# Feature scaling
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
# Training the decision tree model
classifier = DecisionTreeClassifier(criterion='entropy', random_state=0)
classifier.fit(X_train, y_train)
# Predicting the test set results
y_pred = classifier.predict(X_test)
# Evaluating the model
print('Accuracy:', accuracy_score(y_test, y_pred))
print('Confusion Matrix:', confusion_matrix(y_test, y_pred))
print('Classification Report:', classification_report(y_test, y_pred))
# Visualizing the results
sns.countplot(x='Churn', data=data)
plt.title('Customer Churn')
plt.show()
Conclusion:
Customer churn prediction using machine learning is an important tool for businesses to identify customers who are likely to churn and take appropriate actions to retain them. In this article, we discussed the process of building a customer churn prediction model using machine learning in Python.
We started by exploring the Telco Customer Churn dataset and preprocessing the data. We then trained and evaluated several Machine Learning algorithms to find the best-performing model. Finally, we used the trained model to make predictions on new data. Following the steps outlined in this article, businesses can develop effective customer churn analysis strategies and reduce customer churn rates.
Related Articles
Top Tutorials

Made with in Bengaluru, India









- Join AlmaBetter
- Sign Up
- Become an Affiliate
- Become A Coach
- Coach Login
- Policies
- Privacy Statement
- Terms of Use
- Contact Us
- admissions@almabetter.com
- 08046008400
- Official Address
- 4th floor, 133/2, Janardhan Towers, Residency Road, Bengaluru, Karnataka, 560025
- Communication Address
- Follow Us

© 2025 AlmaBetter