Your Success, Our Mission!
6000+ Careers Transformed.
Hierarchical clustering could be a strategy of clustering data into groups or clusters based on their similarity. It may be a type of unsupervised learning, which implies that it does not require labeled information to create expectations.
In hierarchical clustering, the information is at first represented as a set of individual points, and the calculation continues by iteratively consolidating the closest sets of focuses or clusters until all the focuses have a place to a single cluster or to a indicated number of clusters.
There are two fundamental sorts of hierarchical clustering: agglomerative and divisive. The yield of hierarchical clustering is usually represented as a dendrogram, which may be a tree-like diagram that shows the various leveled connections between the clusters. The dendrogram can be utilized to distinguish the ideal number of clusters based on the structure of the tree.
K-means follows an iterative process. It will keep on running until the centroids of newly formed clusters do not change or the maximum number of iterations are reached.
But there are certain challenges with K-means. It always makes spherical clusters. Also, we have to decide the number of clusters at the beginning of the algorithm. Ideally, we would not know how many clusters should we have, in the beginning of the algorithm and hence it a challenge with K-means.
Hierarchical clustering takes away the problem of having to pre-define the number of clusters. So, let’s see what hierarchical clustering is and how it improves on K-means.
Agglomerative clustering may be a sort of hierarchical clustering in which each information point begins as its claim cluster, and clusters are iteratively blended until a halting model is met.
At each iteration, the two closest clusters are merged into a new, bigger cluster. The distance between clusters can be measured employing an assortment of measurements, such as Euclidean distance, cosine similarity, or correlation coefficient.
The method proceeds until all information focuses have a place to a single cluster, or until a ceasing basis, such as a greatest number of clusters or a least remove limit, is met.
The yield of agglomerative clustering can be visualized as a dendrogram, which could be a tree-like diagram that shows the various leveled connections between the clusters. The tallness of the branches within the dendrogram speaks to the separate between clusters at each emphasis.
Agglomerative clustering could be a well known strategy for clustering information since it is simple to execute and can handle huge datasets but can be computationally expensive in case of expansive datasets.
Agglomerative clustering follows a bottom-up approach, where each data point starts as its own cluster, and clusters are merged step by step.
import numpy as np import matplotlib.pyplot as plt from scipy.cluster.hierarchy import dendrogram, linkage from sklearn.cluster import AgglomerativeClustering # Sample data X = np.array([[5, 3], [10, 15], [15, 12], [24, 10], [30, 30], [85, 70], [71, 80], [60, 78], [70, 55]]) # Perform Agglomerative Clustering using scikit-learn agg_clustering = AgglomerativeClustering(n_clusters=3, metric='euclidean', linkage='ward') agg_clustering.fit(X) # Display the cluster labels for each point print(f"Cluster labels: {agg_clustering.labels_}") # Plotting dendrogram for visualizing the hierarchical clusters linked = linkage(X, 'ward') plt.figure(figsize=(10, 7)) dendrogram(linked, orientation='top', distance_sort='descending', show_leaf_counts=True) plt.show()

Divisive clustering is a type of hierarchical clustering in which all data points start in a single cluster and clusters are recursively divided until a stopping criterion is met.
At each iteration, the cluster with the highest variance or the greatest dissimilarity among its data points is split into two smaller clusters. The splitting can be performed using various algorithms such as k-means or hierarchical clustering.
The process continues until each cluster contains only one data point, or until a stopping criterion, such as a maximum number of clusters or a minimum variance threshold, is met.
The output of divisive clustering can also be visualized as a dendrogram, but in contrast to agglomerative clustering, the dendrogram is built from the bottom up, starting with individual data points and building up to the final clusters.
Divisive clustering can produce more meaningful clusters when the data has a clear structure, but it can be computationally expensive and sensitive to the choice of algorithm used for splitting the clusters.
Divisive clustering follows a top-down approach, starting with a single cluster that contains all data points and then recursively splits the clusters.
There is no built-in divisive clustering algorithm in scikit-learn. Below is a sample example by simulating using recursive K-means clustering:
from sklearn.cluster import KMeans import numpy as np # Divisive Clustering Function def divisive_clustering(X, n_clusters=2, depth=0): if len(X) <= n_clusters: return [X] # Stop when we have fewer points than clusters # Apply KMeans clustering to divide the data into two clusters kmeans = KMeans(n_clusters=n_clusters, random_state=0).fit(X) labels = kmeans.labels_ # Recursively apply divisive clustering to each cluster clusters = [] for cluster_id in range(n_clusters): cluster_points = X[labels == cluster_id] if len(cluster_points) > 1: clusters += divisive_clustering(cluster_points, n_clusters) else: clusters.append(cluster_points) return clusters # Sample data X = np.array([[5, 3], [10, 15], [15, 12], [24, 10], [30, 30], [85, 70], [71, 80], [60, 78], [70, 55]]) # Apply Divisive Clustering clusters = divisive_clustering(X, n_clusters=2) # Display clusters for i, cluster in enumerate(clusters): print(f"Cluster {i+1}: {cluster}")

Both approaches offer unique advantages and can be visualized using dendrograms to determine the structure and optimal number of clusters.
In hierarchical clustering, a proximity matrix is a square matrix that stores the distances between each pair of data points. It is used to determine the similarity or dissimilarity between data points or clusters and to merge or split them during the clustering process.
Here's an example of a proximity matrix for five data points:
Let’s take a sample of 5 students:
| Student_ID | Marks |
|---|---|
| 1 | 10 |
| 2 | 7 |
| 3 | 28 |
| 4 | 20 |
| 5 | 35 |
First, we will create a proximity matrix which will tell us the distance between each of these points. Since we are calculating the distance of each point from each of the other points, we will get a square matrix of shape n X n (where n is the number of observations).
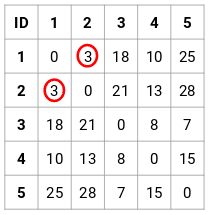
Let’s make the 5 x 5 proximity matrix for our example:
| ID | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 1 | 0 | 3 | 18 | 10 | 25 |
| 2 | 3 | 0 | 21 | 13 | 28 |
| 3 | 18 | 21 | 0 | 8 | 7 |
| 4 | 10 | 13 | 8 | 0 | 15 |
| 5 | 25 | 28 | 7 | 15 | 0 |
The diagonal elements of this matrix will always be 0 as the distance of a point with itself is always 0. We will use the Euclidean distance formula to calculate the rest of the distances. So, let’s say we want to calculate the distance between point 1 and 2:
√(10−7)2=√9=3
Similarly, we can calculate all the distances and fill the proximity matrix.

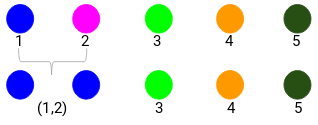
| Student_ID | Marks |
|---|---|
| (1,2) | 10 |
| 3 | 28 |
| 4 | 20 |
| 5 | 35 |
| ID | (1,2) | 3 | 4 | 5 |
|---|---|---|---|---|
| (1,2) | 0 | 18 | 10 | 25 |
| 3 | 18 | 0 | 8 | 7 |
| 4 | 10 | 8 | 0 | 15 |
| 5 | 25 | 7 | 15 | 0 |
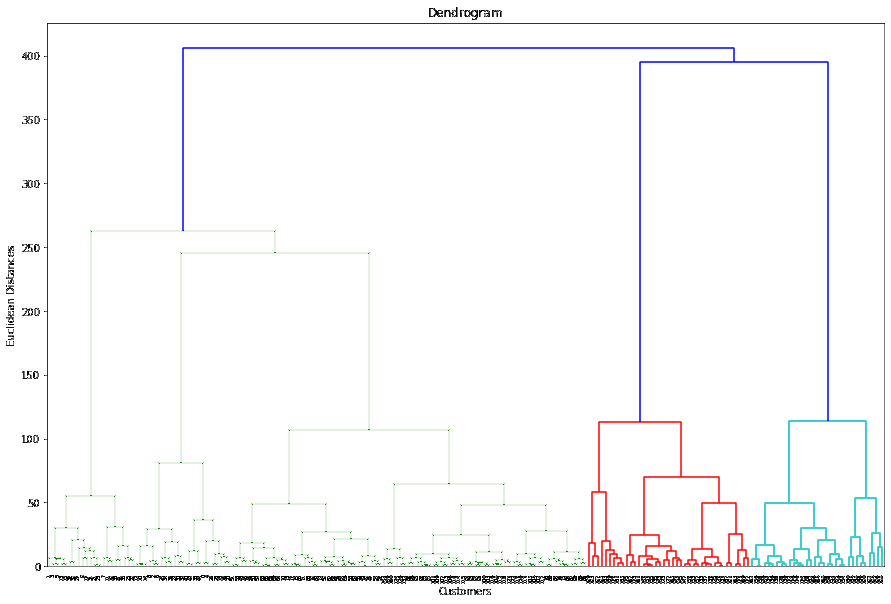
These steps apply to agglomerative clustering, which is the most common type of hierarchical clustering. Divisive clustering, on the other hand, works by recursively dividing the data points into smaller clusters until a stopping criterion is met.
Linkage refers to the criterion used to determine the distance between clusters in hierarchical clustering. Here are some commonly used linkage methods:
The choice of linkage method can have a significant impact on the resulting clusters. For example, single linkage tends to produce elongated clusters, while complete linkage produces more compact clusters. Ward's linkage tends to produce well-separated and evenly sized clusters. Therefore, it is important to choose the linkage method that best fits the characteristics of the data being clustered.
Hierarchical clustering is an unsupervised machine learning technique that groups data points into clusters based on their similarity. Unlike K-means, it does not require the number of clusters to be pre-defined, and it can handle large datasets. There are two main types of hierarchical clustering: agglomerative and divisive. Both methods use a proximity matrix to calculate the distances between data points or clusters.
Answer: a. A method of clustering data points into groups or clusters based on their similarity
Answer: c. Agglomerative and divisive
Answer: d. All of the above
Answer: a. A tree-like diagram that shows the hierarchical relationships between the clusters
Answer: b. Agglomerative clustering merges the closest pairs of points or clusters, whereas divisive clustering recursively divides clusters.
Top Tutorials

Python
Python is a popular and versatile programming language used for a wide variety of tasks, including web development, data analysis, artificial intelligence, and more.

SQL
The SQL for Beginners Tutorial is a concise and easy-to-follow guide designed for individuals new to Structured Query Language (SQL). It covers the fundamentals of SQL, a powerful programming language used for managing relational databases. The tutorial introduces key concepts such as creating, retrieving, updating, and deleting data in a database using SQL queries.

Applied Statistics
Master the basics of statistics with our applied statistics tutorial. Learn applied statistics techniques and concepts to enhance your data analysis skills.
All Courses (6)
Master's Degree (2)
Fellowship (2)
Certifications (2)


