Your Success, Our Mission!
6000+ Careers Transformed.
Overview
Within the healthcare industry, Naive Bayes is utilized to create predictive models that recognize patients with a high chance of developing a certain illness. The algorithm looks at a patient's therapeutic history, as well as demographic and lifestyle factors, to distinguish designs that can be utilized to anticipate the probability of creating a certain illness.
Naive Bayes is a machine learning algorithm used for classification tasks. It is based on Bayes’ Theorem and makes the assumption that each feature of a data point is independent of one another. This allows it to make predictions more quickly than other algorithms. Naive Bayes is often used in text classification problems such as spam detection and sentiment analysis. It is also used in medical diagnosis, fraud detection, and other areas. It is a simple yet powerful algorithm that can yield good results with a minimal amount of training data.
Introduction to Naive Bayes model
The Naive Bayes method is a supervised learning technique that uses the Bayes theorem to solve classification issues. It is mostly utilised in text classification with a large training dataset. The Naive Bayes Classifier is a simple and effective Classification method that aids in the development of rapid machine learning models capable of making quick predictions.
It is a probabilistic classifier, which means it predicts based on an object's likelihood. Spam filtration, sentiment analysis, and article classification are some prominent applications of the Naive Bayes Algorithm.
Bayes Theorem
Bayes' theorem, often known as Bayes' rule or Bayes' law, is a mathematical formula used to calculate the probability of a hypothesis given past knowledge. It is determined by conditional probability. The following is the formula for Bayes' theorem:
Where,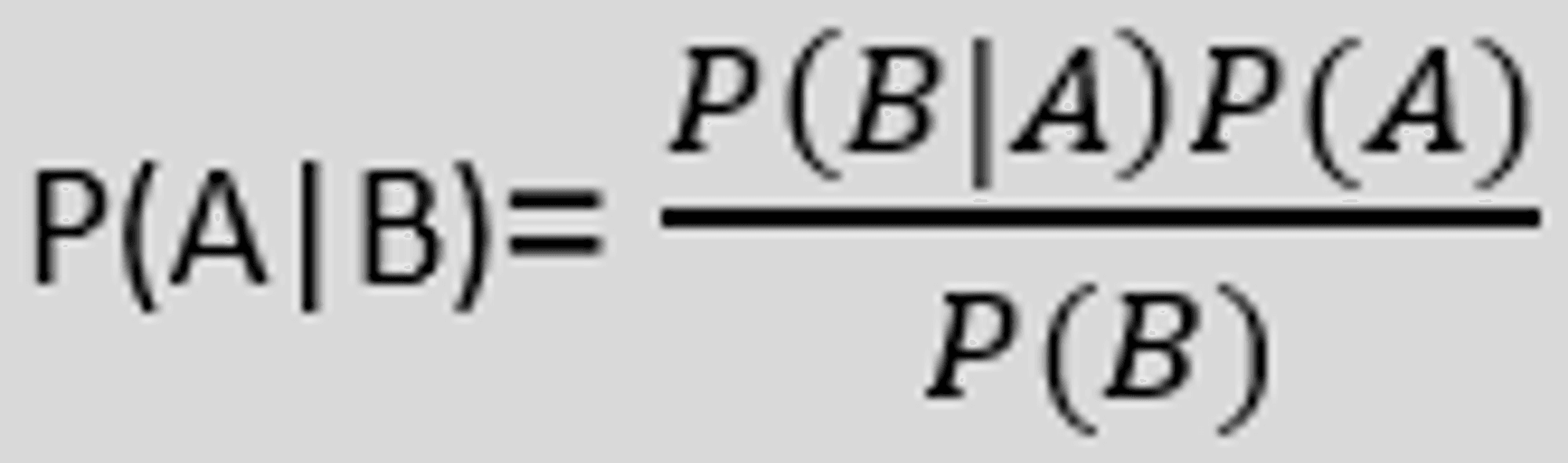
P(A|B) is the posterior probability of hypothesis A on the observed event B. P(B|A) stands for Likelihood probability: the likelihood of evidence provided that a hypothesis is correct. Prior Probability (P(A)) is the probability of a hypothesis before witnessing the evidence. P(B) stands for Probability of Evidence: Marginal Probability.
Probability Theory
Probability theory is a branch of mathematics that deals with the analysis of random events. It is used to quantify the likelihood of certain outcomes in a given situation. It is based on the concept of probability, which is the measure of how likely it is for a given event to occur. Probability theory is used in a variety of fields, including statistics, finance, and machine learning. The main goal of probability theory is to provide a mathematical framework for understanding and predicting random events.
Naive Bayes classifier is a machine learning algorithm that is based on probability theory. It uses Bayes' Theorem to calculate the probability of an event occurring, given certain conditions. It is a supervised learning algorithm, which means it uses labeled training data to build a model for predicting the class of a given observation. The algorithm works by calculating the conditional probability of a given class, given certain features of the data. The probabilities are then used to make predictions about the class of new data. Naive Bayes classifier is a powerful and efficient algorithm that can be used for a variety of tasks, such as text classification, spam filtering, and medical diagnosis.
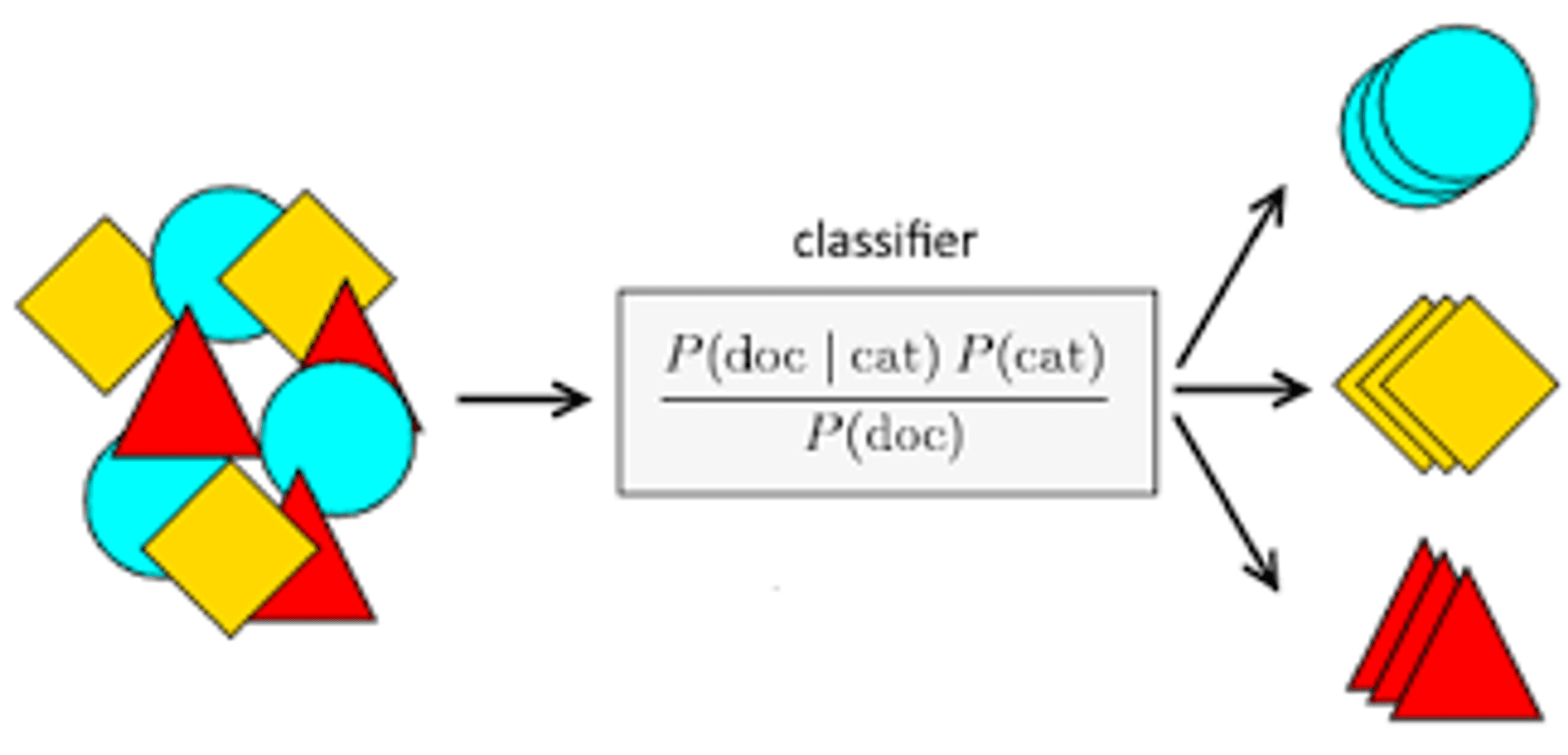
Types of Naive Bayes models
a. Multinomial Naive Bayes:
Multinomial Naive Bayes may be a sort of Naive Bayes classifier which is built on the suspicion of a multinomial distribution of features for each class. This sort of classifier is as a rule utilized for record classification assignments, where each record can be spoken to as a vector of word counts. The likelihood of each class is estimated using the recurrence of each word within the documents of that class. For case, a document classification errand might include classifying emails as either spam or non-spam. The Multinomial Naive Bayes classifier would see at how frequently certain words show up within the emails and utilize that data to calculate the likelihood that an mail is spam or not.
Mathematically, the probability of class c given the document x is defined by the equation:
P(c|x) = P(x|c)P(c) / P(x)
Where P(x|c) is the probability of observing document x given it belongs to class c, P(c) is the prior probability of class c, and P(x) is the marginal probability of observing document x.
b. Bernoulli Naive Bayes: Bernoulli Naive Bayes is also a type of Naive Bayes classifier which is based on the assumption of a Bernoulli distribution of features for each class. This type of classifier is usually used for binary classification tasks, where each feature can take only two values (0 or 1). The probability of each class is estimated using the frequency of the features that take the value 1 in the documents of that class. For example, a binary document classification task might involve classifying emails as either spam or non-spam. The Bernoulli Naive Bayes classifier would look at how often certain words appear in the emails and use that information to calculate the probability that an email is spam or not.
Mathematically, the probability of class c given the document x is defined by the equation:
P(c|x) = P(x1|c)P(x2|c)...P(xn|c)P(c) / P(x1)P(x2)...P(xn)
Where P(x1|c) is the probability of observing the first feature given it belongs to class c, P(x2|c) is the probability of observing the second feature given it belongs to class c and so on, P(c) is the prior probability of class c, and P(x1), P(x2)...P(xn) are the marginal probabilities of observing each feature.
c. Gaussian Naive Bayes: Gaussian Naive Bayes is also a type of Naive Bayes classifier which is based on the assumption of a Gaussian distribution of features for each class. This type of classifier is usually used for continuous data, where each feature is a real-valued number. The probability of each class is estimated using the mean and variance of the features in the documents of that class. For example, a document classification task might involve classifying emails as either spam or non-spam. The Gaussian Naive Bayes classifier would look at how the words appear in the emails and use that information to calculate the probability that an email is spam or not.
Mathematically, the probability of class c given the document x is defined by the equation:
P(c|x) = P(x-μc|σ2c)P(c) / P(x)
Where P(x-μc|σ2c) is the probability of observing document x given it belongs to class c, P(c) is the prior probability of class c, and P(x) is the marginal probability of observing document x.
Preprocessing Text data for Naive Bayes model
Text preprocessing for Naive Bayes involves the following steps:
Input: "This is a sentence."
Output: ["This", "is", "a", "sentence"]
Input: ["This", "is", "a", "sentence"]
Output: ["This", "sentence"]
Input: ["This", "sentence"]
Output: ["This", "sentenc"]
Building a Naive Bayes model
a. Training the model: Training a Naive Bayes model involves calculating the conditional probabilities for the different classes and features of the data. This is done by counting the number of observations for each class and feature, and then dividing this by the total number of observations.
For example, in a dataset containing people's age and gender, we might calculate the conditional probability of being male given that the person is 20 years old. This would be:
P(Male | 20) = # of 20-year-old males / # of 20-year-olds
b. Testing the model: To test a Naive Bayes model, we use Bayes' theorem to calculate the posterior probability of a class given a set of features. This is done by multiplying the prior probability of the class by the conditional probabilities of the features, and then dividing by the prior probability of the features.
For example, using the same dataset as before, we might want to calculate the probability of someone being male given that they are 20 years old and have a job. This would be:
P(Male | 20, Job) = (P(Male) * P(20 | Male) * P(Job | Male)) / P(20, Job)
Advantages and disadvantages of Naive Bayes model
Advantages:
Disadvantages:
Applications of Naive Bayes model
a. Spam Filtering: Naive Bayes is well-suited for identifying spam emails, since it can quickly learn to classify common words and phrases that are often used in spam emails. By using a set of labeled training data, it can quickly identify words that are more likely to appear in spam messages and assign a higher probability that an email is spam.
b. Text Classification: Naive Bayes can be used to classify text into multiple categories, such as news articles, blog posts, or product reviews. By using a set of labeled training data, it can quickly identify words that are more likely to appear in each category and assign a higher probability to that category.
c. Sentiment Analysis: Naive Bayes can be used to classify text into different sentiment classes, such as positive, neutral or negative. By using a set of labeled training data, it can quickly identify words that are more likely to appear in each sentiment class and assign a higher probability to that class.
d. Medical Diagnosis: Naive Bayes can be used to diagnose medical conditions based on patient symptoms. By using a set of labeled training data, it can quickly identify symptoms that are more likely to indicate a certain medical condition and assign a higher probability to that condition.
Implementation
Lets use the iris dataset to implement Naive Bayes algorithm.
The iris dataset is a dataset provided by the scikit-learn library of Python. It contains a total of 150 records, each containing the measurements of petal and sepal lengths and widths of three different species of iris flower (Iris setosa, Iris virginica, and Iris versicolor). The goal of this dataset is to be able to predict the species of an iris flower given its measurements.
In order to implement Naive Bayes algorithm on the iris dataset, the following code can be used:
The code above is utilized to actualize a Naive Bayes algorithm on the Iris dataset. To begin with, the essential libraries are imported, including sklearn.model_selection for splitting the dataset into training and testing sets, sklearn.naive_bayes for the GaussianNB show, and sklearn.metrics for calculating the accuracy of the model.
At that point, the iris dataset is loaded, and the information is split into training and testing sets. The training set is utilized to train the model, and the testing set is utilized to assess the model. The GaussianNB demonstrate is at that point fit to the training set, and the comes about are anticipated on the testing set.
Finally, the accuracy of the model is calculated using the accuracy_score function from sklearn.metrics. The accuracy score of the model is then printed out.
Conclusion
After utilizing Naive Bayes within the healthcare industry, predictive models were created which effectively recognize patients with a high chance of developing a certain illness. The algorithm utilized a patient's restorative history, demographic and lifestyle factors to identify designs that may be utilized to anticipate the probability of creating a certain infection. This empowered healthcare experts to target those at hazard and give preventative care, eventually making a difference to make strides in general patient results.
Key takeaways
Naive Bayes is a simple and powerful supervised machine learning algorithm for classification problems. It is based on the Bayes theorem of probability.
Quiz
1.What type of learning is Naive Bayes?
Answer: A. Supervised Learning
2.What is the main assumption of Naive Bayes?
Answer: C. All features are independent
3.What is the main purpose of Naive Bayes?
Answer: A. Classification
4.What type of data does Naive Bayes work best with?
Answer: B. Categorical data
Top Tutorials

Python
Python is a popular and versatile programming language used for a wide variety of tasks, including web development, data analysis, artificial intelligence, and more.

SQL
The SQL for Beginners Tutorial is a concise and easy-to-follow guide designed for individuals new to Structured Query Language (SQL). It covers the fundamentals of SQL, a powerful programming language used for managing relational databases. The tutorial introduces key concepts such as creating, retrieving, updating, and deleting data in a database using SQL queries.

Applied Statistics
Master the basics of statistics with our applied statistics tutorial. Learn applied statistics techniques and concepts to enhance your data analysis skills.
All Courses (6)
Master's Degree (2)
Fellowship (2)
Certifications (2)


