Your Success, Our Mission!
6000+ Careers Transformed.
Descriptive statistics is a branch of statistics that involves the collection, presentation, and summarization of data to provide a clear and meaningful understanding of the information at hand. It is a fundamental tool for anyone working with data, whether in research, business, or everyday life. Descriptive statistics serves as the foundation for making data-driven decisions, drawing insights, and communicating findings effectively.
The primary goals of descriptive statistics are:
Measures of central tendency are statistical values or summary statistics that provide information about the center or midpoint of a dataset. They are used to describe where the "typical" or "average" value falls within a given set of data points. These measures are fundamental in descriptive statistics and help in understanding the central or representative value of a dataset. The three main measures of central tendency are: mean, median and mode.
These measures provide different perspectives on central tendency and are chosen based on the nature of the data and the research question. They help in summarizing and understanding the distribution of data, making them fundamental tools in statistical analysis and data interpretation.
Definition of Mean
The mean, also known as the average, is a fundamental concept in descriptive statistics used to quantify the central tendency of a dataset. It represents the arithmetic average of a set of values. In other words, it provides a single value that summarizes the typical value of the data points.
Formula for Calculating the Mean
The mean is calculated using the following formula: Here's a breakdown of the formula:
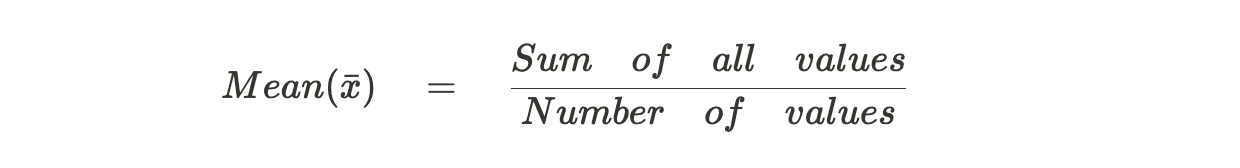
Properties of the Mean
The mean is sensitive to extreme values or outliers in the dataset. If there are values that are significantly higher or lower than the majority of the data, they can have a substantial impact on the mean, potentially skewing its representation of the central tendency.
The mean balances positive and negative deviations from the average. In other words, it considers both values above and below the mean, which helps in understanding the overall distribution of the data.
Changes in the dataset, such as adding or removing data points, can affect the mean. Even a single data point can alter the mean, especially if it is an outlier.
The mean is a useful representation of data in various real-world scenarios. For example, it can be used to calculate the average income of a population, the average temperature over a month, or the average performance of a machine in a manufacturing process.
When to Use the Mean
The mean is appropriate and effective in situations where data is normally distributed and there are no extreme outliers. It is commonly used when you want to understand the typical or average value of a dataset.
However, in cases where the data is skewed or has outliers, the mean may not be the best choice. In such situations, alternatives like the median (middle value) or mode (most frequent value) may provide a more robust measure of central tendency.
The mean finds applications in various fields, including economics (average income), engineering (system performance analysis), biology (average measurements in populations), and many others. Its wide applicability makes it a valuable tool for summarizing data.
Step-by-Step Calculation
To calculate the mean of a dataset:
Numeric Examples
Let's illustrate the calculation process with a numeric example. Consider the following dataset of exam scores:
Step 1: Sum of all values = 85 + 90 + 92 + 78 + 88 = 433
Step 2: Number of values = 5 (there are 5 scores in the dataset)
Step 3:
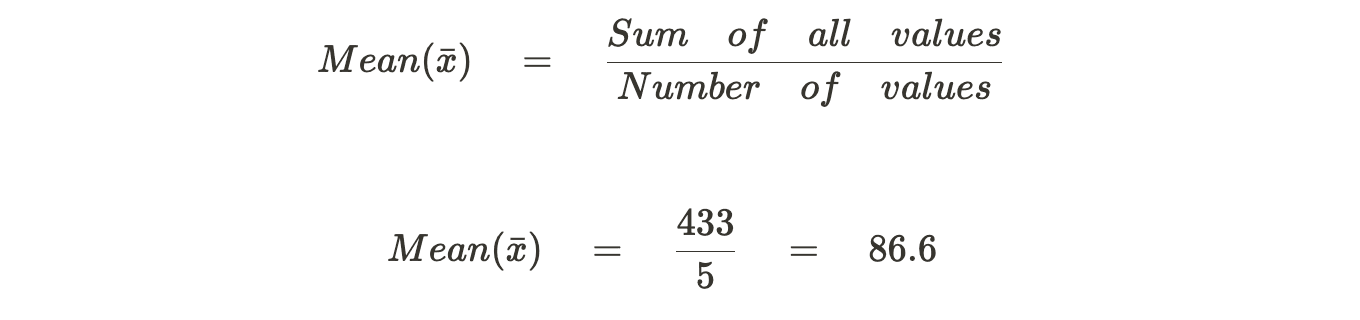
So, in this example, the mean score is 86.6.
Definition of Median
The median is a measure of central tendency in descriptive statistics that represents the middle value of a dataset when it is ordered in ascending or descending order. It divides the dataset into two equal halves, with half of the values falling below and half above the median.
Calculation of Median
To calculate the median:
1. Arrange the dataset in ascending (or descending) order.
2. If the dataset has an odd number of values, the median is the middle value.
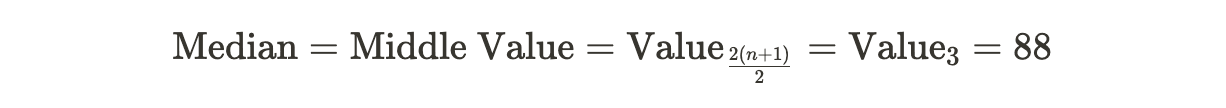
3. If the dataset has an even number of values, the median is the average of the two middle values.
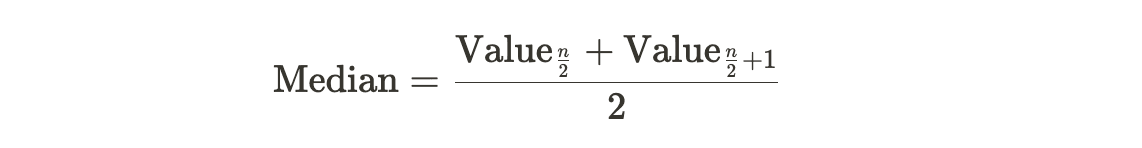
Properties of the Median
1. Robustness to Outliers
One important property of the median is its robustness to outliers. Unlike the mean, which can be significantly influenced by extreme values, the median is resistant to such outliers. This makes it a valuable measure when dealing with skewed or asymmetric datasets.
2. Balancing Positive and Negative Deviations
Similar to the mean, the median balances positive and negative deviations from the central point. It provides insight into the overall distribution of the data.
When to Use the Median
1. Skewed Datasets
The median is particularly useful when dealing with datasets that have a skewed distribution, where the mean may not accurately represent the central tendency. In such cases, the median offers a more representative measure.
2. Ordinal Data
When working with ordinal data (data with ordered categories but no fixed numerical values), the median is often preferred because it retains the ordinal nature of the data.
Example: Finding the Median of a Dataset
Let's consider a practical dataset of exam scores: 85, 90, 92, 78, 88.
Calculation of Median
Odd Dataset
1. Arrange the scores in ascending order: 78, 85, 88, 90, 92.
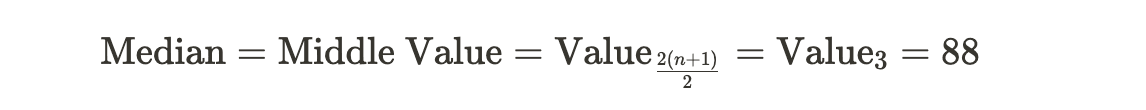
2. Since there is an odd number of values (5), the median is the middle value, which is 88.
Even Dataset :
Dataset: 85, 90, 92, 78, 88, 95
Formula:
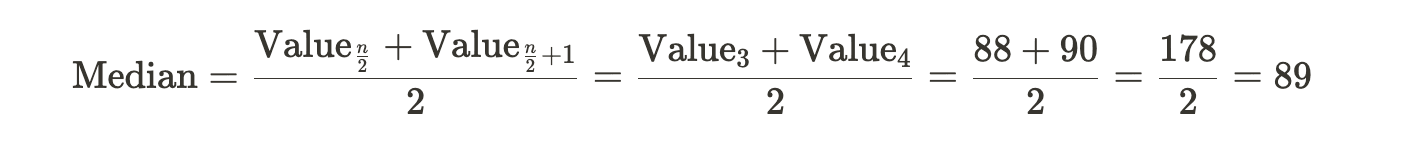
So, in both cases, whether with an odd or even number of values, you can use the formulas to calculate the median.
Interpretation
In the context of this dataset, the median score of 88 represents the middle point, indicating that half of the students scored above 88, and half scored below 88. This provides a robust measure of central tendency, especially if the dataset contains outliers or is not normally distributed.
Definition of Mode
The mode is a measure of central tendency in descriptive statistics that represents the most frequently occurring value in a dataset. In other words, it is the value that appears with the highest frequency.
Calculation of Mode
To calculate the mode:
If there are multiple values with the same highest frequency, the dataset is considered "multimodal," and there can be more than one mode.
Properties of the Mode
One property of the mode is its ability to handle multimodal datasets, where there are multiple modes due to multiple values with the same highest frequency.
The mode can be sensitive to small sample sizes, and in some cases, it may not accurately represent the central tendency if the sample size is very small.
When to Use the Mode
The mode is especially useful for categorical data, where data points fall into categories or groups rather than numerical values.
It is suitable for nominal data, which includes data with categories that have no inherent order.
Example: Identifying the Mode in a Dataset
Let's consider a practical dataset of colors: Red, Blue, Green, Red, Yellow, Blue, Red, Green.
Calculation of Mode
Interpretation
In the context of this dataset, "Red" is the mode, indicating that it is the most frequently occurring color. The mode is particularly useful when you want to identify the most common category or value in a dataset, making it suitable for categorical or nominal data.
Measures of dispersion, also known as measures of variability, are statistical measures that quantify the extent to which data points in a dataset spread out or deviate from a central value, such as the mean, median, or mode. These measures provide valuable insights into the distribution and spread of data, helping to understand the degree of variation within a dataset.
The primary purpose of measures of dispersion is to describe the level of diversity, dispersion, or scatter in the data. They are essential tools for assessing the reliability and consistency of data, identifying outliers, and making informed decisions in various fields such as statistics, economics, finance, quality control, and research.
Definition of Variance
Variance is a statistical measure that quantifies the spread or dispersion of a dataset. It indicates how much individual data points deviate from the mean (average) of the dataset. In other words, it measures the average of the squared differences between each data point and the mean.
Calculation of Variance
To calculate the variance for a dataset:
The formula for calculating the sample variance (denoted as *s^*2) is:
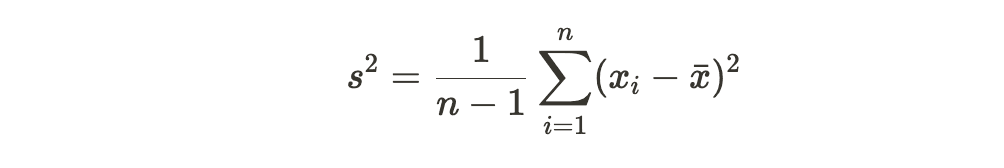
Where:
Properties of Variance
Variance provides a measure of how data points are spread out around the mean. A higher variance indicates greater dispersion, while a lower variance implies that data points are closer to the mean.
Variance is sensitive to outliers or extreme values in the dataset. A single extreme value can significantly impact the variance, making it a useful tool for identifying unusual data points.
Interpretation of Variance
A higher variance suggests greater variability in the data, meaning that data points are more spread out. Conversely, a lower variance implies that data points are closer to the mean, indicating less variability.
Real-World Application
In various fields such as finance, economics, and quality control, variance is used to assess risk, analyze performance, or ensure product consistency. It helps in understanding and managing uncertainty and variability.
Example: Calculating Variance for a Set of Data
Consider a dataset of exam scores: 85, 90, 92, 78, 88.
Calculation of Variance
1. Find the mean (_x_ˉ) of the dataset:
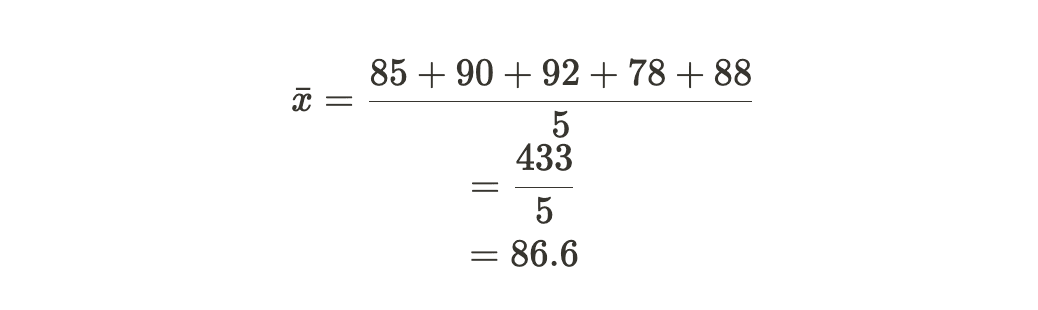
2. Calculate the squared differences from the mean for each data point:
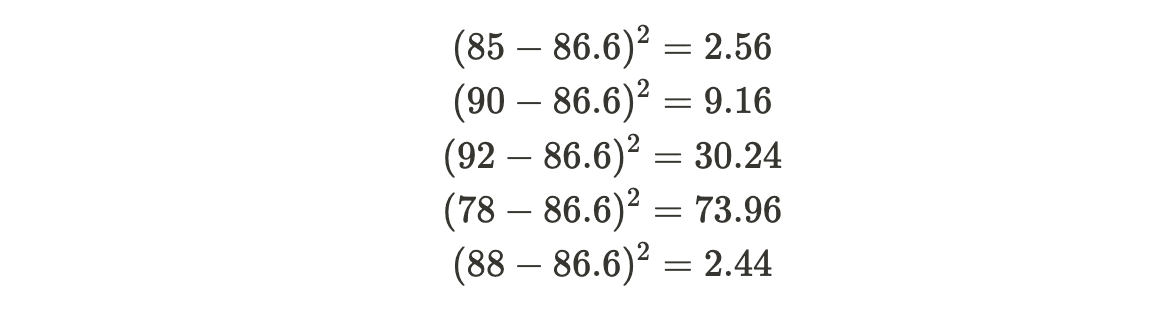
3. Sum the squared differences:
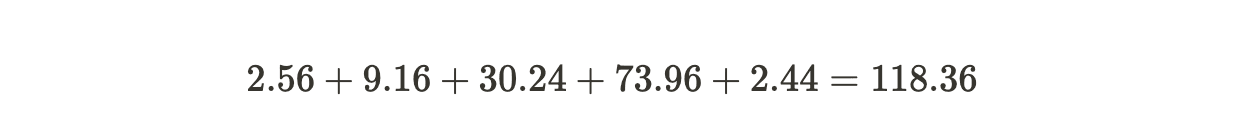
4. Divide the sum by the total number of data points minus one (n-1):
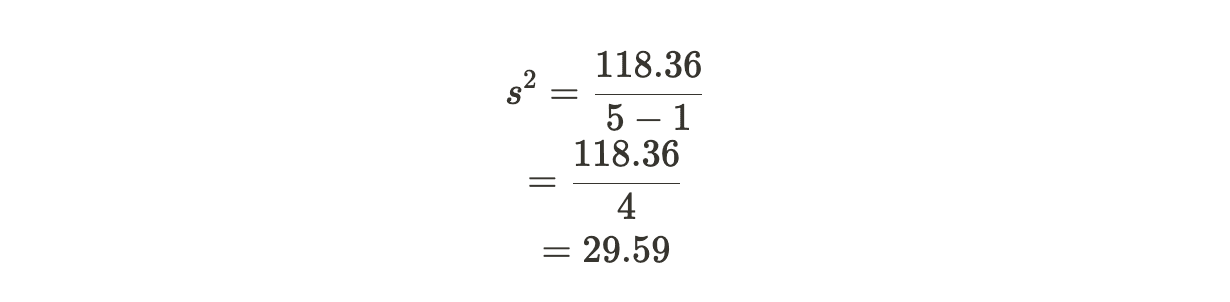
So, the sample variance for this dataset is approximately 29.59.
Definition of Standard Deviation
The standard deviation is a statistical measure of the dispersion or spread of a dataset. It quantifies how individual data points vary from the mean (average) of the dataset. A smaller standard deviation indicates that data points are closer to the mean, while a larger standard deviation suggests that data points are more spread out.
Calculation of Standard Deviation
The formula to calculate the sample standard deviation (s) is as follows:
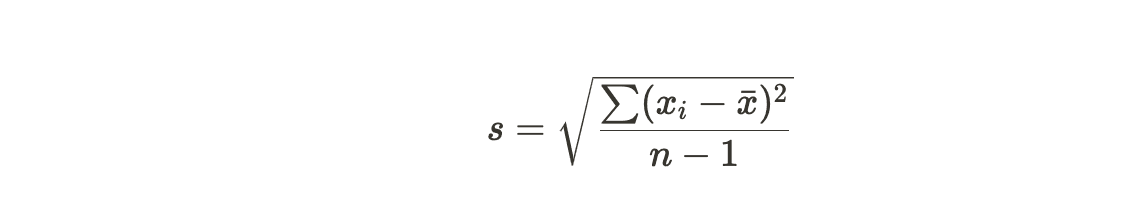
Where:
Relationship with Variance
The standard deviation is the square root of the variance (*s^*2). In other words:
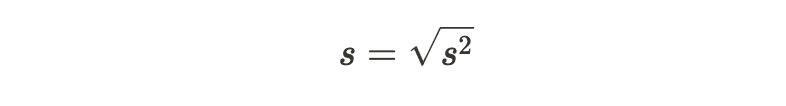
It provides a more interpretable measure of data spread because it is in the same unit as the original data. While variance measures the spread in squared units, standard deviation expresses the spread in the original units of the data.
Interpretation of Standard Deviation
A higher standard deviation indicates greater variability in the data, suggesting that data points are more dispersed from the mean. Conversely, a lower standard deviation implies that data points are closer to the mean, indicating less variability.
Standard deviation is often used in the context of confidence intervals and hypothesis testing. Smaller standard deviations provide higher confidence that data points are closely clustered around the mean.
Example: Computing Standard Deviation for a Data Sample Consider a dataset of exam scores: 85, 90, 92, 78, 88.
Calculation of Standard Deviation:
1. Find the mean (_x_ˉ) of the dataset:
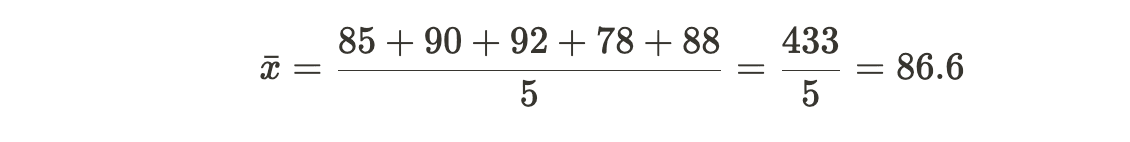
2. Calculate the squared differences from the mean for each data point:
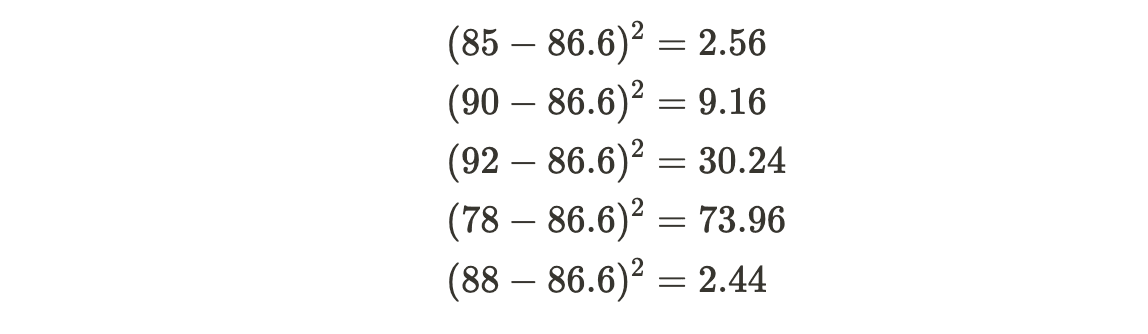
3. Sum the squared differences:
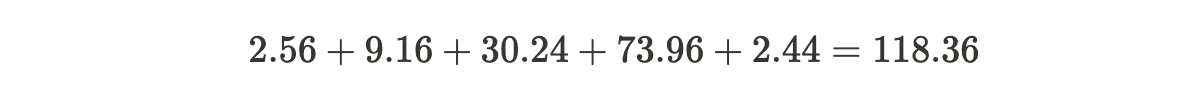
4. Divide the sum by the total number of data points minus one (_n_−1):
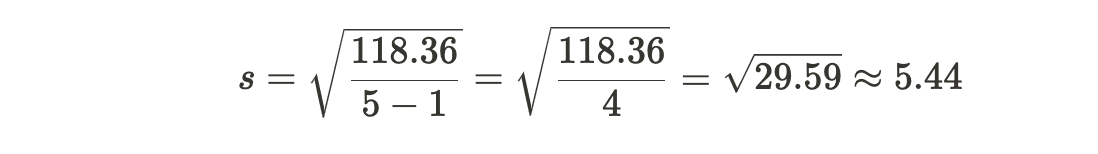
So, the sample standard deviation for this dataset is approximately 5.44.
Skewness is a statistical measure that indicates the asymmetry of the data distribution. It helps us understand whether the data is concentrated more on one side of the mean compared to the other. Positive skewness means the data is skewed to the right (tail on the right side), while negative skewness indicates skewness to the left (tail on the left side). The formula for calculating skewness (S) is often expressed as:
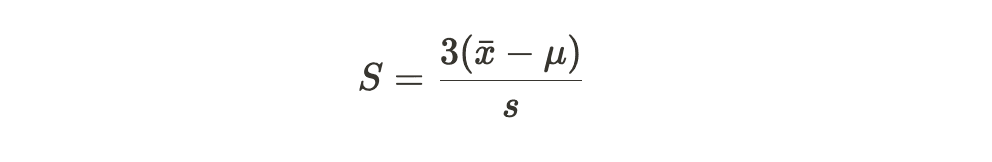
Where:
Kurtosis is a statistical measure that quantifies the "tailedness" or peakiness of the data distribution. It helps in understanding whether the data has heavy or light tails compared to a normal distribution. Positive kurtosis indicates heavier tails, while negative kurtosis indicates lighter tails.
The formula for calculating kurtosis (\(K\)) is often expressed as:
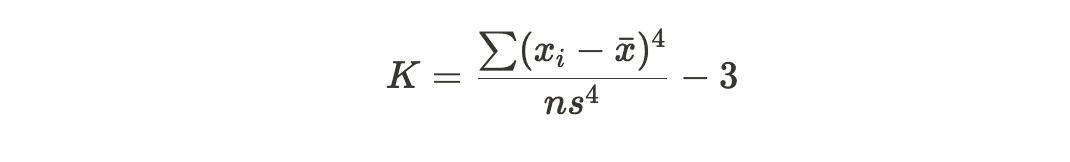
Where:
Measures of skewness and kurtosis provide insights into the shape and distribution of data, helping in the analysis of non-normal or skewed datasets.
Example 1: Analyzing Test Scores
Example 2: Financial Data Analysis
Example 3: Quality Control in Manufacturing
In conclusion, descriptive statistics empowers data-driven decision-making by simplifying complex datasets and revealing critical data characteristics. Its wide-ranging applications underscore its significance as an indispensable tool for understanding and harnessing the power of data.
Descriptive statistics plays a pivotal role in the realm of data analysis and decision-making across diverse fields, including research, business, and everyday life. It serves as the foundation for comprehending and drawing meaningful insights from data. Key takeaways from this exploration of descriptive statistics include:
1. For a moderately skewed distribution, the mean and median are respectively 26.8 and 27.9. What is the mode of the distribution?
Answer
Given,
Mean = 26.8
Median = 27.9
Using the relationship between mean, median and mode,
Mode = 3 Median – 2 Mean
= 3 × 27.9 – 2 × 26.8
= 83.7 – 53.6
= 30.1
Therefore, the mode of the distribution is 30.1.
2. If mean of 14, 13, 18, 16, k, (k + 3) is 13, then what will be the mean of k, 8, 9, 11, 5, 10, 6?
Answer
To find the mean of the numbers in the second set, we need to first determine the value of 'k' from the information given in the first set.
Given that the mean of the first set (14, 13, 18, 16, k, k + 3) is 13, we can calculate the sum of these numbers and set it equal to the mean multiplied by the number of elements:
Mean = (Sum of numbers) / (Number of elements)
We have:
13 = (14 + 13 + 18 + 16 + k + (k + 3)) / 6
Now, let's solve for 'k':
13 = (61 + 2k) / 6
To isolate 'k', multiply both sides of the equation by 6:
78 = 61 + 2k
Subtract 61 from both sides:
2k = 78 - 61 2k = 17
Now, divide by 2:
k = 17 / 2 k = 8.5
So, 'k' is equal to 8.5.
Now that we know the value of 'k,' we can calculate the mean of the second set (k, 8, 9, 11, 5, 10, 6):
Mean = (k + 8 + 9 + 11 + 5 + 10 + 6) / 7
Substitute the value of 'k':
Mean = (8.5 + 8 + 9 + 11 + 5 + 10 + 6) / 7
Now, calculate the sum:
Mean = (57.5) / 7
Mean ≈ 8.2143 (rounded to four decimal places)
So, the mean of the second set (k, 8, 9, 11, 5, 10, 6) is approximately 8.2143.
3. If the distribution is negatively skewed, then the:
a. mean is more than the mode
b. median is at right to the mode
c. mean is less than the mode
d. mean is at right to the median
Answer
mean is less than the mode
4. In a data set, the range refers to:
a. The average of the data values.
b. The difference between the maximum and minimum data values.
c. The most frequently occurring data value.
d. The spread or dispersion of data around the mean.
Answer:
b. The difference between the maximum and minimum data values.
Explanation: The range of a data set is calculated as the difference between the maximum value and the minimum value in the data set. It provides a measure of the spread or variability in the data.
Top Tutorials

Python
Python is a popular and versatile programming language used for a wide variety of tasks, including web development, data analysis, artificial intelligence, and more.

SQL
The SQL for Beginners Tutorial is a concise and easy-to-follow guide designed for individuals new to Structured Query Language (SQL). It covers the fundamentals of SQL, a powerful programming language used for managing relational databases. The tutorial introduces key concepts such as creating, retrieving, updating, and deleting data in a database using SQL queries.

Data Science
Learn Data Science for free with our data science tutorial. Explore essential skills, tools, and techniques to master Data Science and kickstart your career
All Courses (6)
Master's Degree (2)
Fellowship (2)
Certifications (2)


